
How can integrating a Tiny Language Model (TLM) into your enterprise AI stack to improve performance and reduce costs?
Integrating a self‑hosted Tiny Language Model (TLM) for routine user queries dramatically lowers latency and infrastructure costs while preserving data privacy. For complex tasks, seamlessly route to larger LLMs like GPT-4 & Gemini for advanced processing.
Table of Contents
- What is a Tiny Language Model (TLM)?
- Why use TLMs for simple queries?
- How did we implement our TLM integration?
- What benefits did we observe?
- Where can you apply this approach?
- How to get started with TLM integration
- TL;DR Summary
What is a Tiny Language Model (TLM)?
A Tiny Language Model (TLM) is a lightweight, self-hosted neural network designed for task-specific applications like customer support, internal automation, and real-time personalisation. Unlike large language models, TLMs deliver fast, efficient inference on local infrastructure with minimal compute resources. They offer businesses more control, lower latency, and enhanced data privacy, making them ideal for edge deployment and enterprise use cases. For a working example, visit our SLM on Hugging Face

Why use TLMs for simple queries?
Simple, frequent questions often do not require heavyweight inference. Examples include:
- What are your working hours?
- How do I reset my password?
- Where can I view my orders?
- Routing these to TLMs reduces API calls to Cloud LLMs, cutting costs and latency by up to90%.
How did we implement our TLM integration?
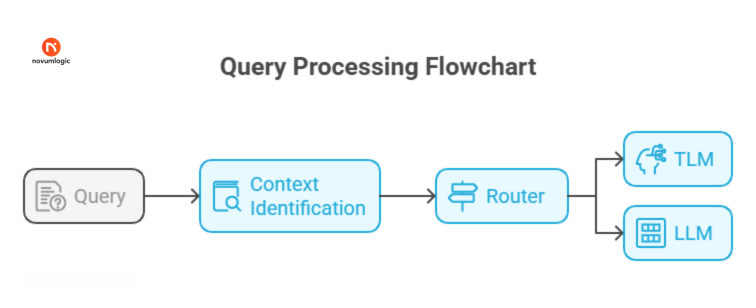
1. Context Detection with Lightweight Embeddings
- Each incoming query first passes through a semantic context identification module using sentence embeddings (via sentence transformers) and rule-based classifiers.
- These help label the query as belonging to categories like “billing,” “technical support,” “order tracking,” or “FAQs”.
2. Semantic Routing Engine
Once classified, our semantic router decides where the query should go:
- Knowledge base, if an exact match or rule applies
- Tiny Language Model (TLM), for dynamic but simple questions like “Where’s my order?”
- LLMs like GPT-4 & Gemini, for multi-turn, complex, or nuanced requests
3. Self-hosted TLM Inference
We self-hosted our model to maximize performance and data privacy:
- It is trained on 30k+ annotated support chats. It covers 27 customer intents, 11 categories, and real-world language variations, making it highly effective for automating customer service across industries.
- Deployed on a cloud VM using Kubernetes for easy scaling and management.
- CPUs are sufficient for inference, eliminating the need for GPU clusters.
4. Monitoring & Performance Tracking
- All TLM responses are logged with metadata: latency, confidence score, and resolution status.
- A feedback loop retrains the model monthly on new low-confidence examples.
5. Model Lifecycle
We adopted a lightweight MLOps cycle for the TLM:
- Auto-labelling of missed intents
- Retraining on real-world feedback
- Versioned deployments via Helm charts for rollback safety
What benefits did we observe?
- Faster Response Times: Millisecond‑scale answers for routine tasks.
- Lower Infrastructure Costs: Reduced API spend and GPU usage.
- Enhanced Privacy: Data processed on‑premises, reducing compliance risk.
- Improved UX: Instant replies for FAQs; GPT-4 & Gemini reserved for deep engagement.
Where can you apply this approach?
- AI‑powered customer support
- Enterprise chatbots
- FAQ automation
- Workflow assistants
- Internal IT helpdesks
How to get started with TLM integration?
- Choose a base model.
- Fine‑tune on domain‑specific dialogues.
- Deploy self‑hosted inference (Docker/Kubernetes).
- Configure semantic router (embedding + rules).
- Monitor performance and iterate.
TL;DR
- TLMs handle routine queries with minimal resources.
- Semantic routing ensures complex tasks still leverage GPT-4 & Gemini.
- Benefits: Reduced latency, lower costs, and stronger data privacy.
Ready to optimize your AI infrastructure?
Contact our team to schedule a demo.


.webp)
.svg)


